How DB Trail guarantees a recovery would actually be correct: Data Validation

Every recovery tool makes the same promise: if something goes wrong, it will give your data back exactly as it was. The problem is that you usually find out if its true during an incident, with the table already gone. That is the worst possible moment to learn that your history had a gap in it.
So DB Trail does not ask for your trust. It lets you break the promise on a normal day, in CI, before it matters. This post is about the part people ask about the least and should ask about the most: not how DB Trail captures or recovers, but how it checks that the recovery would be correct.
It is not only one check. The data passes through three places where it can go wrong, and DB Trail checks each one on its own:
- Capture: did every change really get recorded, with no silent gap in the stream?
- At rest: did the stored history survive on disk without bit-rot or a half-written file?
- Reconstruction: does the recovery chain, a baseline snapshot plus the indexed deltas on top of it, actually reproduce the original rows?
A failure in any one of these makes the other two useless. A perfect reconstruction of data you never captured is still wrong. So the checks go in the order the data travels.
1. Was every change captured: stream continuity
DB Trail captures by reading the MySQL binlog as a replication stream. The failure that matters here is not “the stream stopped”, you would notice that. It is the silent gap: the stream resumes after a hiccup, a slice of events in the middle was never recorded, and nothing tells you. Now the index looks healthy and complete, and it is quietly missing an hour of changes.
DB Trail already detects unfillable binlog gaps. What matters for verification is that it always reports the verdict, as part of bintrail status:
=== Stream ===
Bintrail ID: abc123de-0000-0000-0000-000000000001
Mode: gtid
Events indexed: 986655
Continuity: no gaps in the captured range (not a liveness check)That line is one of exactly three states:
| Verdict | Meaning |
|---|---|
no gaps in the captured range (ok) | The captured range is contiguous, nothing was dropped. |
⚠ GAP LOST at <ts> (gap_lost) | An unfillable gap was stamped. The index is valid only up to the gap. |
not evaluated (legacy index…) (unknown) | An older index without the gap-detection columns. The state cannot be confirmed, so it is never reported as a false ok. |
Two decisions in there are the difference between a check you can trust and a check that lies to keep a dashboard green.
First, unknown is its own state, it is never silently turned into ok. If DB Trail cannot prove the stream was contiguous, it says so. A check that answers “fine” when it does not actually know is worse than no check, because it gives you a confidence that you did not earn.
Second, it fails closed in CI. status is a report by default, but bintrail status --fail-on-gap exits non-zero on gap_lost or unknown. So a nightly job can assert that capture is provably whole and break loudly the moment it is not:
bintrail status --index-dsn "$IDX" --format json \
| jq -e '.stream.continuity.status == "ok"'When data really was lost this is not a quiet log line, it is a banner that tells you the index up to the gap is still good for recovery, but you need to re-baseline to resume clean capture. The point is that you hear about it early, not in the middle of a restore.
2. Did the stored bytes survive: at-rest integrity
Old history is rotated out of MySQL into Parquet files, first on local disk, then on S3. The Parquet readers, DuckDB’s parquet_scan and parquet-go, trust the bytes. There is no CRC check and no pragma to force one. So a file corrupted by bit-rot or a half-finished write is read back as truth, and a corrupted baseline gives you a confidently wrong reconstruction.
DB Trail closes that with a _MANIFEST sidecar written next to each baseline snapshot: a CRC-32C over every Parquet file’s bytes at write time. Every local baseline read path (reconstruct, the cascade path in recover, and the query engine’s snapshot reads) re-hashes the file and compares before it uses a single row. On a mismatch it fails loud with a corruption error instead of returning garbage.
Two limits here have to be stated with precision, because a post about correctness that promises too much is worthless.
This is bit-rot and partial-write protection, it is not tamper protection. The manifest is a separate file from the data, so corruption of one does not hide corruption of the other, but someone who can rewrite a Parquet file can rewrite its manifest too. Real tamper-evidence needs signing or an external registry, and that is a separate, bigger job on purpose.
And S3 read-validation is still on the roadmap. Today the CRC check runs on the local read paths. The S3 read paths stream directly through DuckDB without keeping a byte-identical local copy to hash against, so instead of a false assurance they log an honest one-time warning that the durable copy was not validated on read. If you want the strongest at-rest guarantee right now, keep a local tier of your recent baselines. DB Trail prefers to be exact about where the line is instead of implying a check that is not running.
3. Does the chain reproduce the data: bintrail verify
This is the check DB Trail would not ship without. Sections 1 and 2 prove the inputs are whole and intact. This one proves the output: that a baseline snapshot plus the indexed binlog deltas on top of it would rebuild the right rows.
The claim is stated the way the tool states it, because it matters. verify does not prove your data is correct, it tries to disprove it and tells you when it cannot. That is not being careful with the words, it is the only honest thing a check like this can say. A clean run means nothing thrown at the recovery chain could break it.
Baseline-anchored mode, the default, and why it is drift-free
Run it with no --source-dsn:
bintrail verify --index-dsn "$IDX" --baseline-dir /data/baselinesFor each table, verify takes your two most recent baselines, reconstructs the older one forward by applying the indexed binlog events up to the newer baseline’s exact binlog anchor, and fingerprints the result against the newer baseline.
The important part is subtle: both sides are at-rest snapshots, neither one is the live table. That makes the check drift-free. It cannot be fooled by a change that happened on the source after capture, because it never looks at the source. It isolates the one thing you care about, the capture-and-reconstruct chain itself. And because it reads no live source, it has zero production impact, so you can run it right after every bintrail baseline, or on a cron.
There is also a --source-dsn live-source mode that reconstructs a point in time and compares it against the real table. That one reads the whole table off the live server, so it is an off-peak tool. It is useful, but it is the mode that can be confused by drift after capture, which is why baseline-anchored is the default.
The verdicts, including the one most tools hide
Each table comes back as one of three results, and the third one is where an honest tool and a marketing one part ways.
- match: the reconstruction reproduces the comparison exactly.
- mismatch: they differ. The chain would not reproduce this table. Go find out why before you ever rely on it.
- inconclusive:
verifycould not prove the table either way, and this is never reported as a failure. Maybe there is no predecessor baseline yet, the index is behind the anchor, the primary key is an unsupported type, there is a coverage gap, or it is a value type this version still cannot compare byte for byte.
inconclusive exists because the alternative, quietly calling an unprovable table a match, is exactly the false confidence this whole post is against. If DB Trail cannot prove it, it says so.
Wiring it into CI
The exit codes are built for a pipeline:
- Non-zero on any mismatch or error, or when comparable tables existed but none of them could be proven (all inconclusive). One inconclusive table does not fail the run, a run that proved nothing does.
- Zero when a source has only one baseline, because there is nothing to compare it against yet. This is reported, not failed.
- Non-zero when no baselines are found at all, because that is a misconfiguration, not “nothing to do”.
So a clean exit means a real thing: nothing disproved the recovery chain. That is a sentence you can put in a runbook.
The same check, from the console
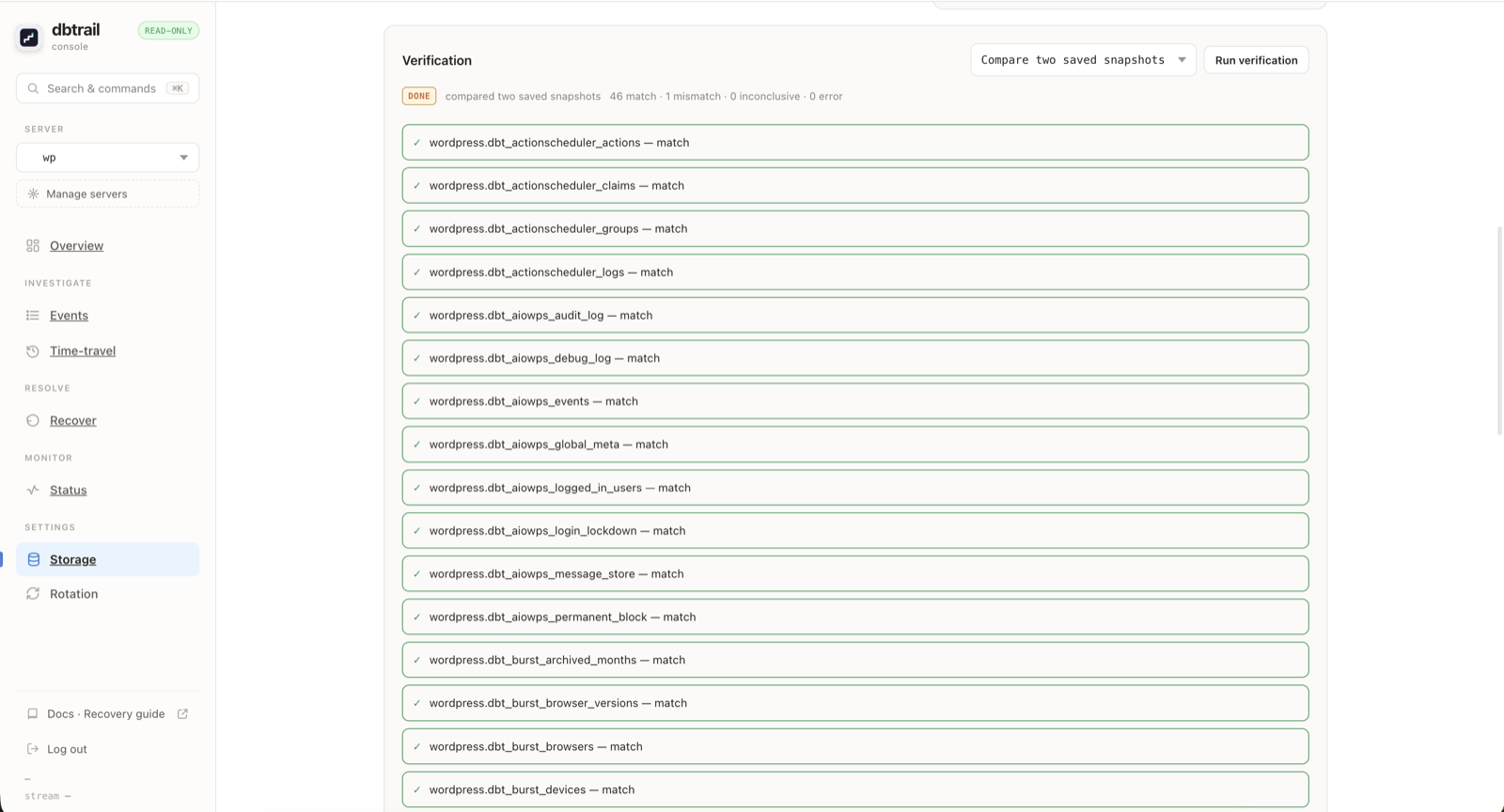
Everything above runs from the command line, but the same check is also in the console UI, for the people who do not live in a terminal. Under Storage there is a Verification panel with the same two modes in a dropdown: Compare two saved snapshots, which is the baseline-anchored drift-free default, and Compare against your live database, which is the live-source mode and carries the same warning that it reads the whole table and is better run outside busy hours. You pick a mode, press Run verification, and it lists every table with its verdict, match, mismatch, inconclusive or error, with a running count at the top while it works.
It is the same engine as the CLI, only with a face. The console is read-only, it never writes to your source or your index, so a teammate can run a verification without shell access and without touching production.
4. When it does not match: verify --explain
A red “mismatch” you cannot dig into is just anxiety. So in baseline-anchored mode, --explain prints exactly what diverged, right under the per-table verdict:
bintrail verify --index-dsn "$IDX" --baseline-dir /data/baselines --explainIt shows the differing primary keys, and for changed rows, the differing columns with the reconstructed value next to the new baseline’s value. It gets there by re-running the same reconstruction the verdict came from, byte-identical by construction, so there is no scratch database, no live source, and no external diff tool that could add a discrepancy of its own. The explanation is the verdict, told row by row.
Why four checks and not one
You could imagine a single “is my data OK” button. DB Trail does not build that on purpose, because the four checks respond to different questions and fail for different reasons.
| Check | Question | What it catches |
|---|---|---|
| Stream continuity | Did every change get recorded? | A silent gap in capture |
| At-rest CRC | Did the stored bytes survive? | Bit-rot, a partial write |
verify | Does the chain reproduce the rows? | A broken reconstruction |
verify --explain | Which rows are wrong? | (drill-down, not a gate) |
A green light on one of them tells you nothing about the others. Folding them into a single number would only hide which layer broke, and on the day you actually need a recovery, “something is wrong somewhere” is not an answer.
So do not take DB Trail’s word that any of this works. Point bintrail verify --explain and bintrail status --fail-on-gap at your own index, in CI, on a normal afternoon. The best thing that can happen with a recovery tool is that you have already watched it tell you the truth, including the uncomfortable truth once in a while, long before you actually depend on it.